Reproducibility in Scientific Computing
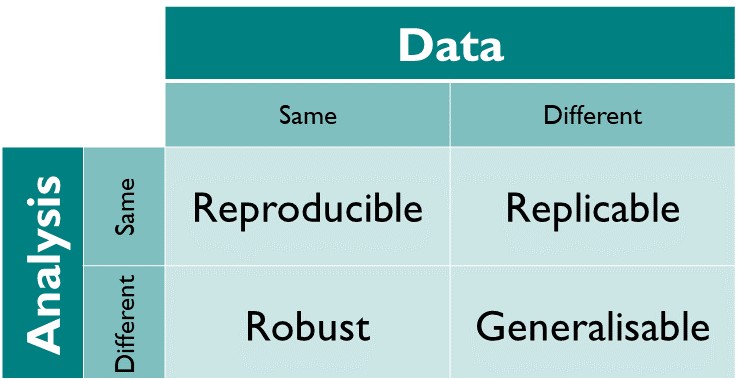
What is reproducibility?
In scientific research, a result is:
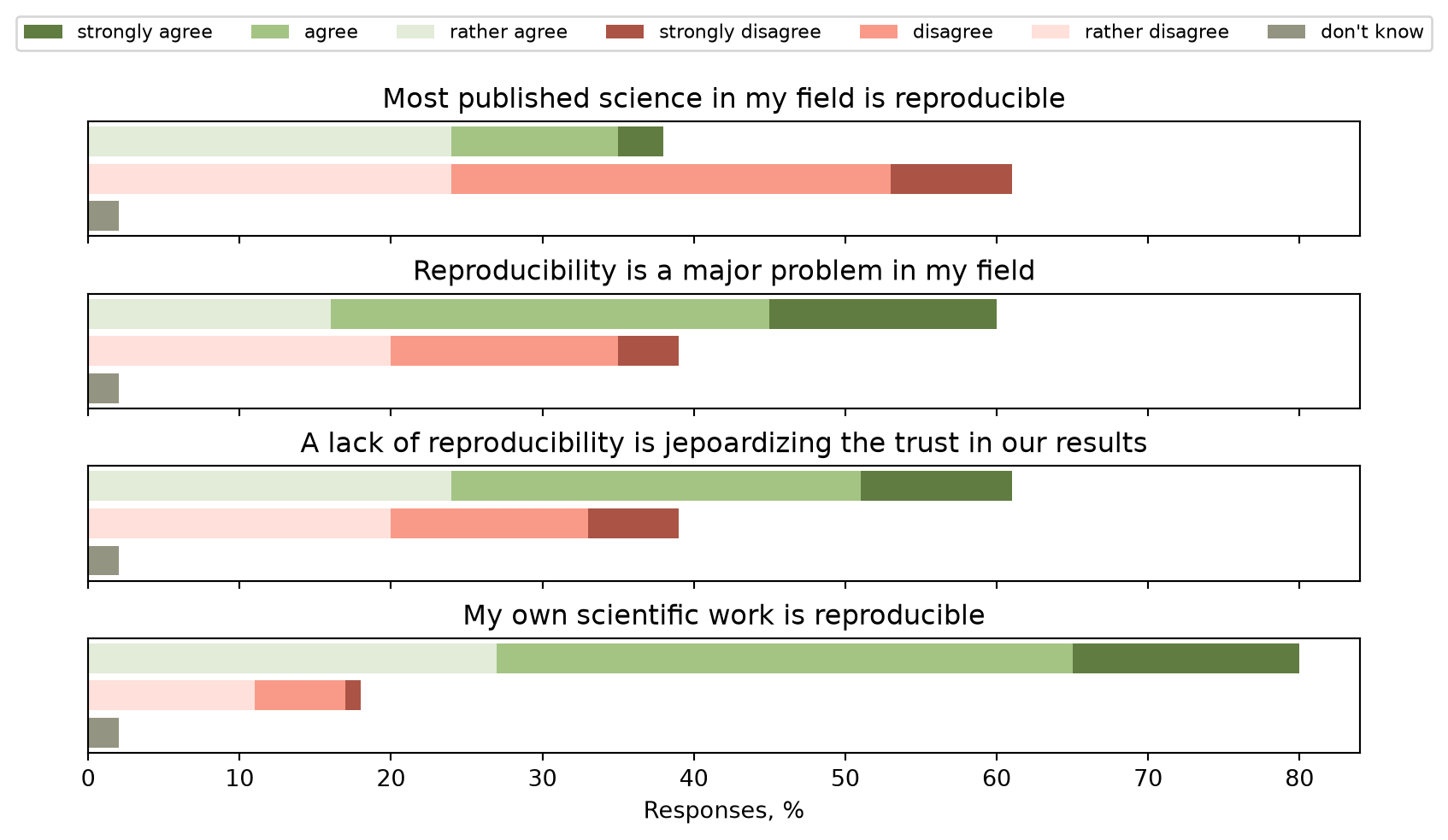
Reproducibility in Earth sciences
Reasons for non-reproducibility:
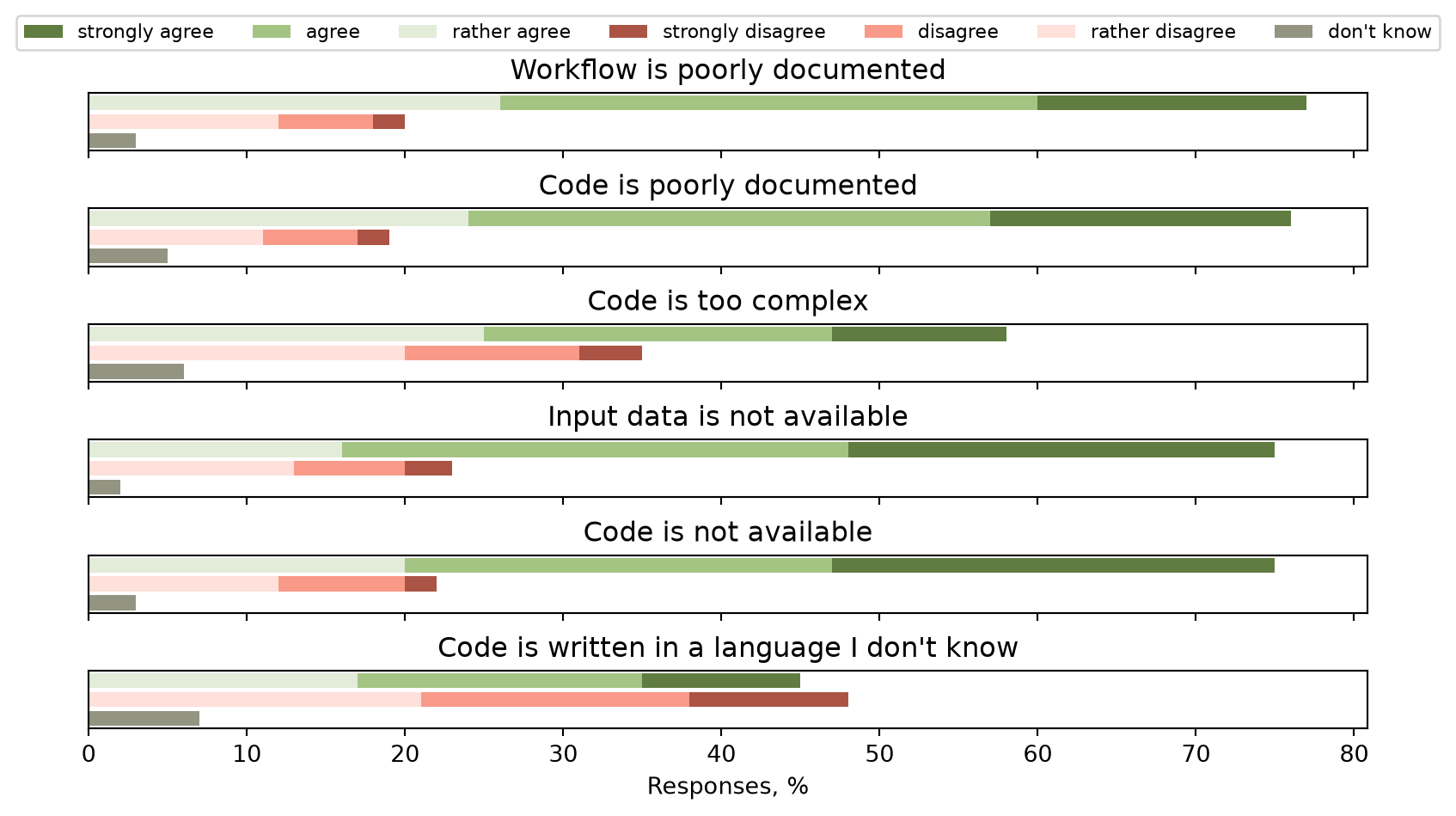
How to declare data dependencies
- Links to publicly accessible data dependencies
- Zenodo or some other long term solution
- Reference specific versions of the data
- Use DOI from hosting platform
- Ideally automate the fetching of the data
System dependencies - Containers
- Containers package up code and all dependencies
- Virtualised operating system
- Faster than a virtual machine with many of the benefits
- Examples:
- Docker (Closed source but popular)
- Podman (Open source alternative)
- Apptainer (HPC focused/compatible)
- Portable and cross-platform
![]()

![]()
README
- Markdown file at the project root
- Should contain:
- Description of project
- Dependencies
- Instructions on building/running
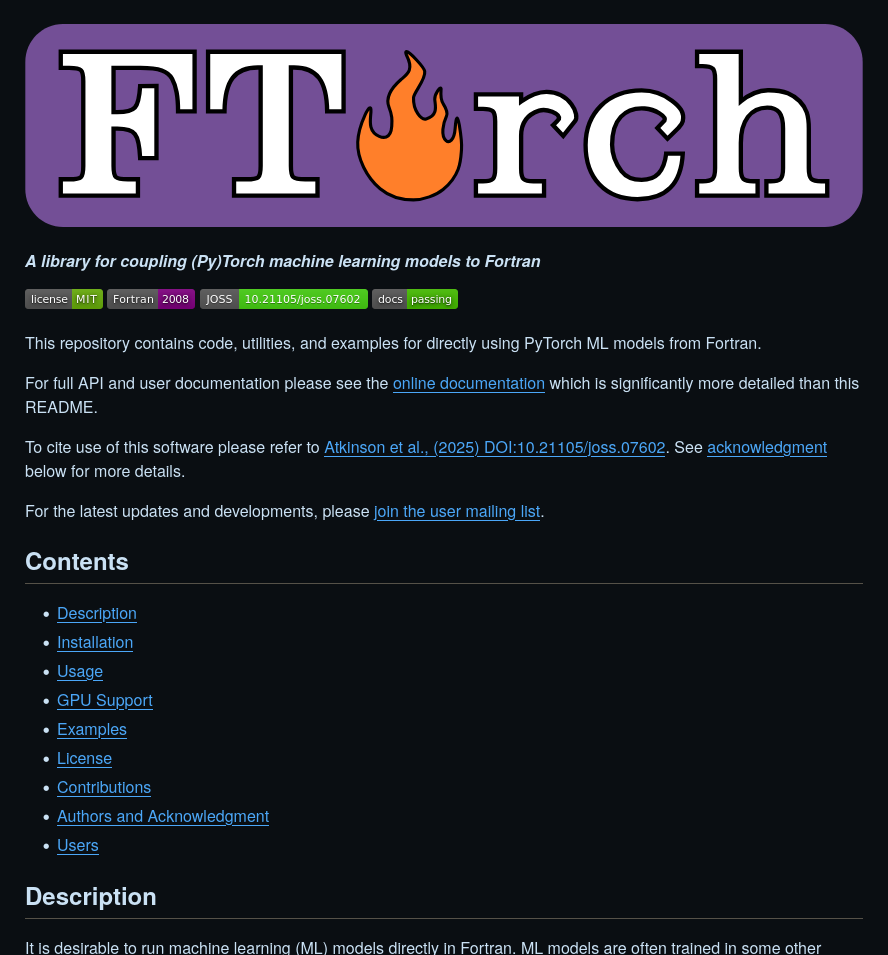
The FAIR principles were first introduced for data, and later adapted for research software (FAIR4RS) 1.
FAIR stands for
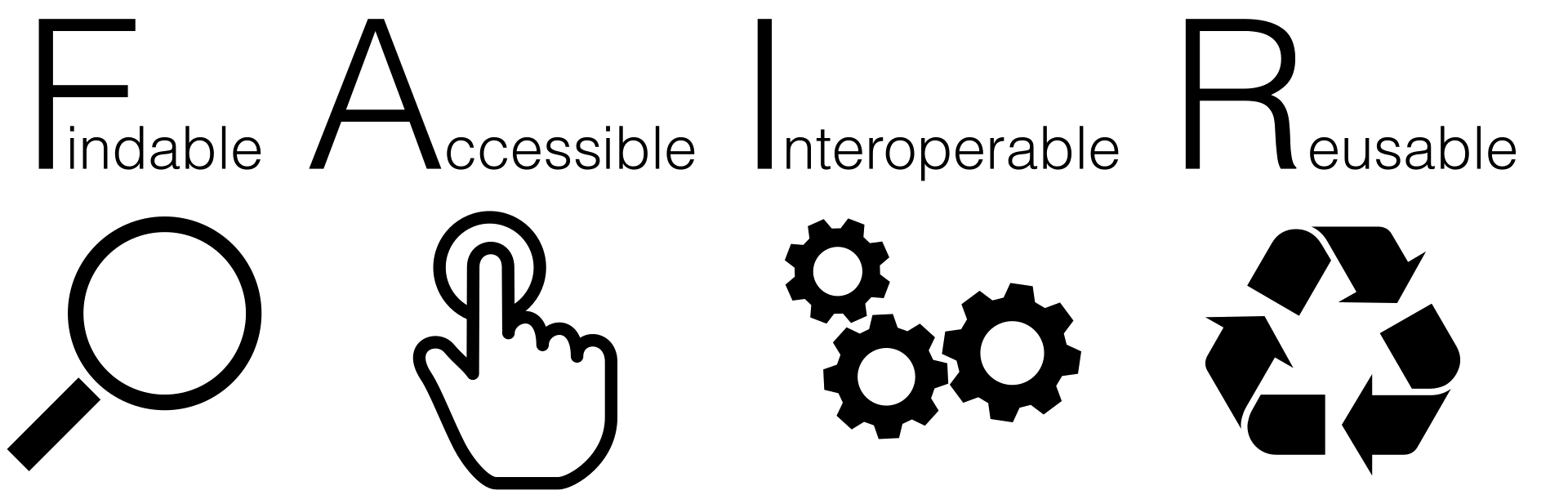
![]() UK Reproducibility Network
UK Reproducibility Network
 UK Reproducibility Network
UK Reproducibility NetworkPeer-led consortium within the UK, international networks
National Steering Group, local and institutional groups
Training, events, engaging with stakeholders
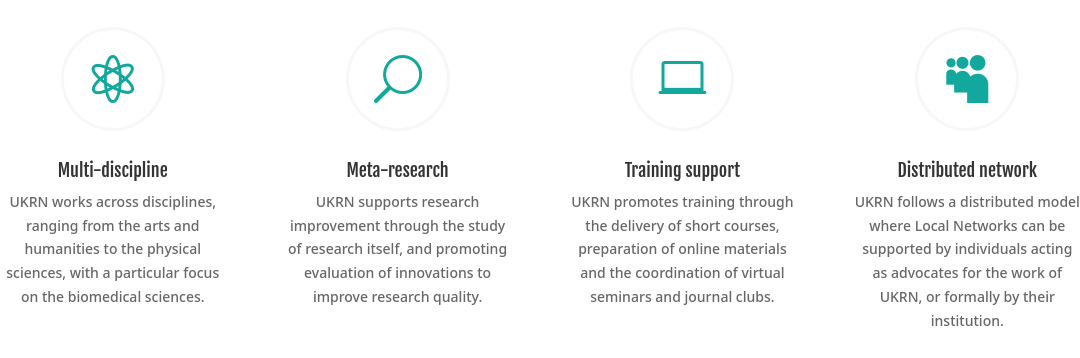
![]() RIOT Science
RIOT Science
 RIOT Science
RIOT Science- Reproducible Interpretable Open Transparent
- Groups at universities (mostly Psychology, mostly UK)
- Conferences, events, seminars open to everyone
The Turing Way
- Handbook
- Community
- Collaboration
![]() ACM Reproducibility Badges
ACM Reproducibility Badges
 ACM Reproducibility Badges
ACM Reproducibility Badges
- Applied to research artifacts e.g. papers
- Used across ACM journals and conferences
- Rewards researchers for reproducibility efforts

![]() SC Reproducibility Initiative
SC Reproducibility Initiative
 SC Reproducibility Initiative
SC Reproducibility Initiative
SC (formerly Supercomputing), The International Conference for High Performance Computing Networking, Storage, and Analysis
Initiative started in 2015
- Artifact Descriptions (ADs) optional for the first few years
- used in Student Cluster Competition
Then gradually made mandatory for more categories/prizes
- Computational Results Analysis (CRA)
- Artifact Evaluation (AE) appendix still optional
AD/AE committee evaluates appendices and recommends ACM badge awards
Reproducibility challenge introduced 2021
![]() ReproHack
ReproHack
Challenge: Reproduce the results of a paper in one day!
Started in 2016 and 2017 as satellite events of OpenCon (inspired by a course by Owen Petchey)
Developed further by Anna Krystalli in her SSI fellowship
More events, a team formed, remote ReproHacks became a thing….
ReproHack Hub launched in 2021
ReproHack Hub
- Material and checklists for organisers
- Paper database
- Evaluation forms
- Events listing
- Support through ReproHack Slack
ICCS Hacktoberfest 2026


Comments